How much would one hour of downtime actually cost your business? Not just in lost revenue, but in missed deadlines, damaged client relationships, and hours of recovery time?
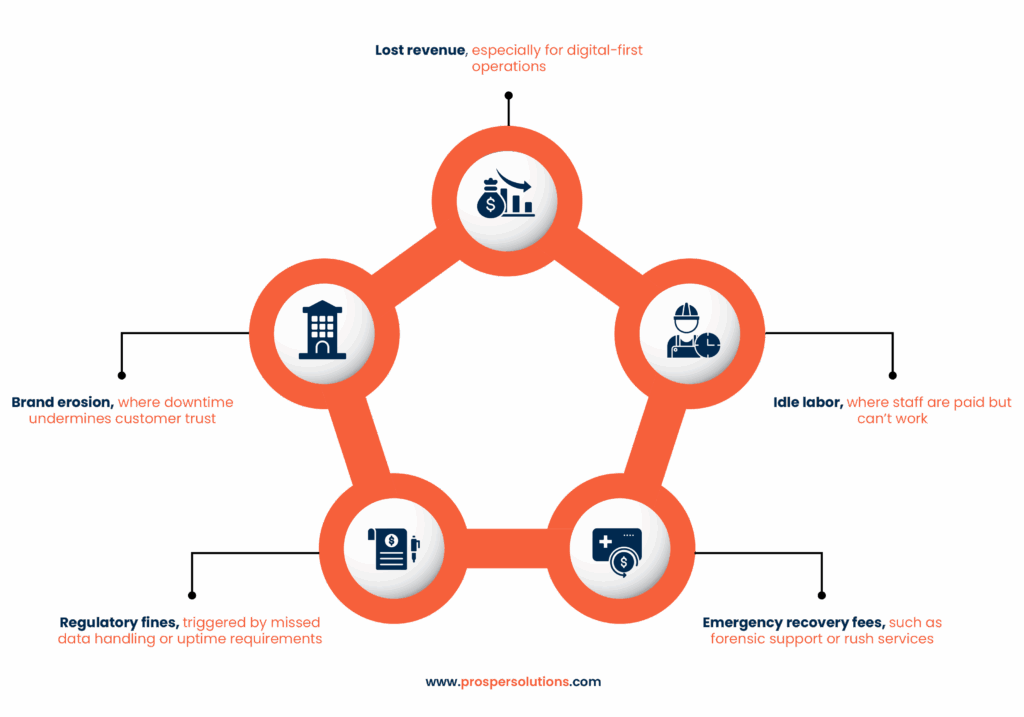
Most small and mid-sized businesses do not run that calculation until it is too late. And by then, the numbers can be shocking. Research shows the cost of IT downtime can reach over $5,000 per minute on average. But in practice, the financial hit goes far beyond that when you add recovery fees, productivity loss, compliance penalties, and reputational damage.
This is not just a problem for global enterprises.
Every business that relies on cloud apps, remote work, or online transactions is at risk. And yet, many teams still treat downtime as an inconvenience rather than a business risk that deserves proactive planning.
If you are still relying on reactive fixes or fragmented backups, this blog will help you rethink your risk. We will explore what downtime really costs, what causes it, and how cyber security and layered planning can protect your operations before things break.
The Real Cost of IT Downtime
Let’s talk about the number first, recent studies show the average cost of IT downtime in 2025 has climbed to $9,000 per minute, or $540,000 per hour for many mid-sized businesses. For large enterprises, that average per-minute figure can surpass $23,000, bringing the hourly totals to well over $1 million for the most critical or regulated industries.
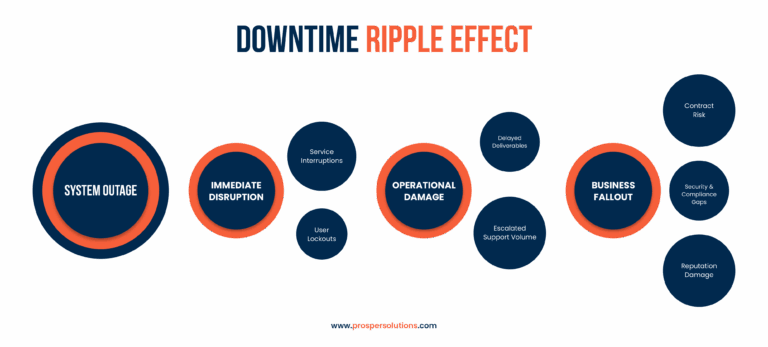
These numbers reflect not only lost revenue but also operational disruption, penalties, and substantial reputation damage. Small and mid-sized organizations face ripple effects that extend far beyond the immediate disruption.
Empty heading
Even a brief outage during a peak period can create lasting damage. For most small and mid-sized IT firms, recovery doesn’t just mean getting systems back online, it means rebuilding trust, re-engaging customers, and re-aligning service-level agreements.
What makes this worse is when downtime is triggered by preventable causes, such as malware infections or unpatched vulnerabilities. These risks are often underestimated until they become front-page problems and if you want to know more about the nature of different threats, you can refer to this read.
For Mid-Size and Large Enterprises
We often think of downtime as a challenge mostly for smaller teams right? But the truth is, the stakes only get higher as an organization grows. Mid-sized and large enterprises may have more tools and talent, but they also have more moving parts, more systems to manage, and far more to lose if things go wrong.
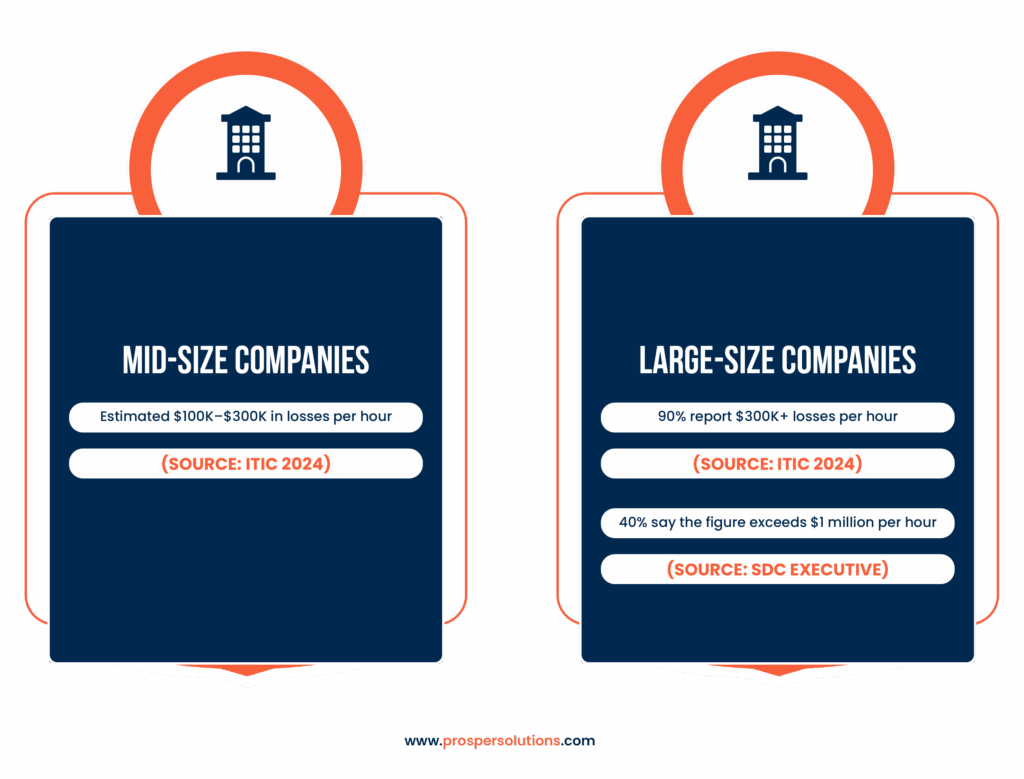
Mid-sized companies often sit in a risky middle zone. They rely on complex IT operations but may not have the depth of resources that larger firms do. A single hour of system failure can sideline hundreds of employees and disrupt millions in client operations.
For large enterprises, the cost of a brief outage can escalate from uncomfortable to catastrophic. Clients expect performance. Regulators expect compliance. And the bigger you are, the more visible the fallout becomes when systems go dark.
What Drives Downtime in SMB Settings?
Downtime usually isn’t caused by a single error; it stems from a combination of weak spots that pile up over time. For many businesses, these are the common stress points they see that escalate into major outages:
Outdated Hardware & Unsupported Software
Systems get old, and software reaches end-of-life, often without updates. When servers, routers, or applications fail without backup or redundancy, operations can grind to a halt. Without proactive maintenance, these aging technologies become ticking time bombs that lead to high recovery costs and system-wide disruption.
Misconfiguration & Human Mistakes
Manual configuration changes, forgotten patching, or inconsistent user setups can lead to hidden vulnerabilities. One small error like wrongly assigned permissions or disabled security settings, can cascade into system failure or a prolonged outage, making the cost of IT downtime sprawl far beyond immediate fixes.
Ransomware and Emerging Cyber Risk Exposure
Even if your team stays on top of patches, a ransomware attack or breach can take everything offline in seconds. These types of incidents are more frequent for SMBs lacking a layered cyber security framework. Too often, systems are compromised before detection, resulting in serious downtime, data loss, and recovery expenses. Learn more about overlooked vulnerabilities in our blog on legacy software risks — Why outdated browsers still expose your organization.
Absence of Tested Disaster Recovery & Continuity Plans
Many SMBs have a nominal continuity plan stored in a document, but never test it. When disaster hits, the process falls apart. Without regular drills, backup validation, or failover testing, recovery efforts can be chaotic, and painfully slow. This absence of preparation amplifies both the financial and reputational impact of every outage.
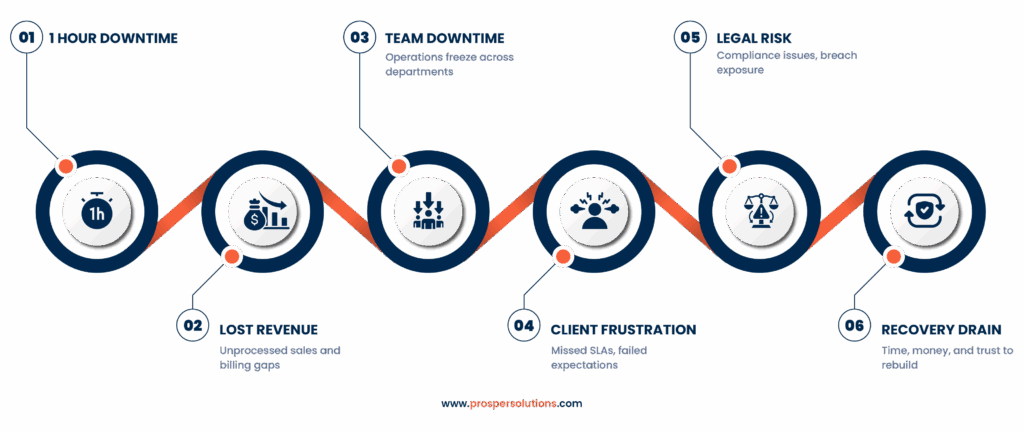
Calculating Your Downtime Risk
Not every outage disrupts operations equally. But without a clear framework, small and mid-sized teams often default to reactive decisions, responding only after damage is done.
To move from guesswork to strategy, start by calculating the true cost of IT downtime:
Downtime Risk = (Downtime Minutes × Revenue per Minute) + Recovery Costs
This equation reveals more than just a dollar amount. It helps teams prioritize. For example, if your operations bring in $5,000 per hour, a two-hour outage could mean $10,000 lost, before factoring in recovery labor, lost productivity, or potential compliance fines.
To build smarter defenses, go further than just cost. Use a risk management lens to score each system across three dimensions:
- Criticality – How essential is the system to daily operations?
- Availability – What’s its historical uptime and reliability?
- Exposure – How vulnerable is it to cyber threats, misconfigurations, or hardware failure?
This is where cyber security risk management plays a strategic role. Instead of reacting to every alert, IT leaders can map real business impact to infrastructure and apply resources where failure would be most costly.
It’s not about predicting every disruption. It’s about preparing for the ones that would hurt most.
6 Layers of Resilience Every SMB Should Build
For any small and mid-sized firm, the ability to recover quickly from failure is not a luxury.
It is a necessity. Without layered defenses in place, even a short disruption can lead to cascading failures, client dissatisfaction, and compliance exposure. The cost of IT downtime grows with every missed safeguard, often without teams realizing it until it is too late.
This is why cyber security and risk management must be approached as a cross-functional discipline, not just an IT checklist. The following six layers represent a scalable foundation for operational resilience, especially for small and mid-sized teams with limited internal resources.
One – Disaster Recovery and Business Continuity Planning
A documented DR/BC plan is your frontline defense against chaos. It defines your recovery priorities, identifies system dependencies, and assigns clear roles in the event of a failure. For example, knowing which applications must be restored within 15 minutes versus those that can wait 2 hours drastically reduces recovery time and stress. These plans must be updated quarterly and aligned with current infrastructure and client SLAs.
Two – Automated Backups with Redundancy
Backups are only valuable if they work and can be restored under pressure. Automated, scheduled backups should include both local and off-site (cloud) copies. Local backups provide speed, while cloud backups add protection from ransomware, fire, or equipment damage. Backup testing should also be automated, verifying file integrity and restore paths.
Three – Continuous Monitoring and Intelligent Alerting
Most outages begin with small signals, anomalous traffic, CPU spikes, or unusual login attempts. Without real-time monitoring, these signs go unnoticed until damage is done. Implement monitoring across servers, endpoints, and cloud workloads. Intelligent alerting ensures your team focuses on real threats, not false positives. This guide from Microsoft offers insight into how effective observability supports modern IT environments, particularly for the Azure cloud users.
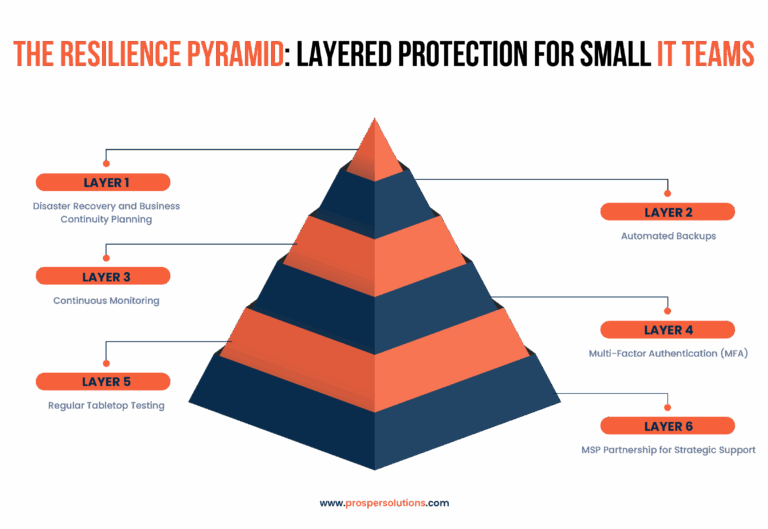
Four – Multi-Factor Authentication (MFA) and Endpoint Protection
Stolen credentials and unprotected endpoints are the most exploited attack vectors. Enforcing MFA across all critical systems even for internal tools, adds a powerful layer of control. Pair this with device-level protection including firewalls, anti-malware, USB restrictions, and encryption. Cyber security at the endpoint level prevents lateral movement inside your environment.
Five – Regular Tabletop Testing
A recovery plan is only as good as the team executing it. Tabletop exercises simulate common failure scenarios, from ransomware to server outages and test your team’s speed, clarity, and coordination. Invite both technical and non-technical stakeholders to participate. These drills help identify miscommunications and improve your risk management posture without risking real damage.
Six – MSP Partnership for Strategic Support
Small and mid-sized businesses can benefit significantly from working with a Managed Service Provider (MSP).
A reliable MSP brings advanced tools, compliance expertise, and 24/7 coverage that most internal teams cannot sustain alone. They act as an extension of your team, helping implement proactive safeguards instead of reacting after an incident.
Common Myths That Lead to Downtime Blind Spots
Many organizational leaders assume downtime won’t hit them hard, until it does. These myths are not just misconceptions. They are quiet risk multipliers that inflate the cost of IT downtime and weaken cyber resilience.
Many small and mid-sized firm leaders assume downtime won’t hit them hard, until it does.
Myth 1: “We’re too small to be targeted”
This is one of the most persistent blind spots among small and mid-sized organizations. Cybercriminals often exploit automation to identify exposed or under protected systems, and smaller teams typically lack layered defenses or 24/7 monitoring. Being “under the radar” is no protection when your network is scanned daily by bots looking for open doors.
Myth 2: “Our backups are enough”
A backup is only helpful if it’s complete, current, and restorable under pressure. Many businesses find out too late that their backups don’t include key applications or cloud environments. Others experience significant delays retrieving data because no one tested the restore process in advance. Resilience depends not just on having data saved but knowing exactly how and when it can be recovered.
Myth 3: “We’ll fix it when it happens”
Downtime is rarely just a technical issue. It creates a chain reaction: delayed operations, customer frustration, lost revenue, and compliance exposure. Waiting until failure strikes to build a response plan ensures higher recovery costs, slower timelines, and preventable mistakes.
An Insight: Downtime planning should be treated as a business continuity function, not a last-minute technical fix, understand the difference.
Many small teams assume they are safe simply because nothing has gone wrong yet. They believe their size makes them less likely to be targeted or that their backups are enough to recover from anything. But without testing those assumptions, they end up underprepared when the unexpected happens.
Test it before you’re forced to react.
Real risk management is not about doing more. It is about knowing exactly where your weak points are. A few focused drills or scenario reviews can reveal issues before they grow into real problems. The teams that recover fastest are usually the ones who prepared while things were still calm.
Closing Notes
We’re not done with this topic, the landscape of downtime, risk, continuity, what the data reveal is too vast to fully cover in one read.
But our goal here was to make sure you leave with enough clarity to take real action. Whether you’re planning ahead or catching up, you now have the context to navigate these risks in the real world.
The cost of IT downtime is not just a number on a spreadsheet. It affects people, operations, client trust, and long-term momentum. And while technology plays a big role, lasting protection comes from strategy, preparation, and consistent review. That is what separates companies that recover quickly from those that stall.
If your organization is looking to improve resilience, Prosper Solutions can help. We work with small and mid-sized teams to strengthen cyber security, reduce exposure, and build practical systems for business continuity. Whether you need support with risk management or simply want to make your existing plan more reliable, we’re here when you’re ready.
FAQs
In IT, downtime refers to any period when a system, service, or network becomes unavailable or unusable. This could be due to unexpected outages, maintenance, hardware failures, software errors, or cyber attacks.
Preventing downtime requires more than just backups. IT teams should build a multi-layered defense strategy that includes:
- A documented disaster recovery and business continuity (DR/BC) plan
- Automated, redundant backups stored locally and in the cloud
- 24/7 system monitoring and real-time alerts
- Regular tabletop testing and incident response drills
- Strong endpoint protection and multi-factor authentication (MFA)
For small businesses, an hour of downtime can result in $10,000 to $100,000 in losses, depending on how reliant they are on IT systems. For mid-sized organizations, that number often climbs to $300,000 or more when productivity, sales, and recovery labor are factored in.
Because waiting for a breach is far more expensive than preventing one. Cybercriminals often target small businesses precisely because they assume security is weak. Proactive investment in IT security solutions for small businesses helps avoid costly downtime, protects customer trust, and ensures compliance with industry regulations.
Responding to downtime requires a structured and fast-moving approach. Here’s how IT teams should manage it:
- Detect the Issue Quickly
Use monitoring tools to identify outages in real time before users report them. - Assess the Scope
Determine which systems, users, or services are affected and how critical the impact is. - Activate Your Response Plan
Follow your documented incident response process to assign roles, prioritize actions, and begin mitigation. - Isolate and Contain the Problem
Prevent the issue from spreading by isolating affected infrastructure or shutting down compromised systems. - Communicate with Stakeholders
Keep internal teams, executives, and end users updated with accurate information to maintain trust and minimize disruption. - Restore Services Safely
Once the root cause is addressed, bring systems back online in a controlled and tested manner. - Review and Improve
After recovery, conduct a post-incident review to analyze what went wrong and update your policies, tools, or training to prevent it from happening again.